어휘분석이란?
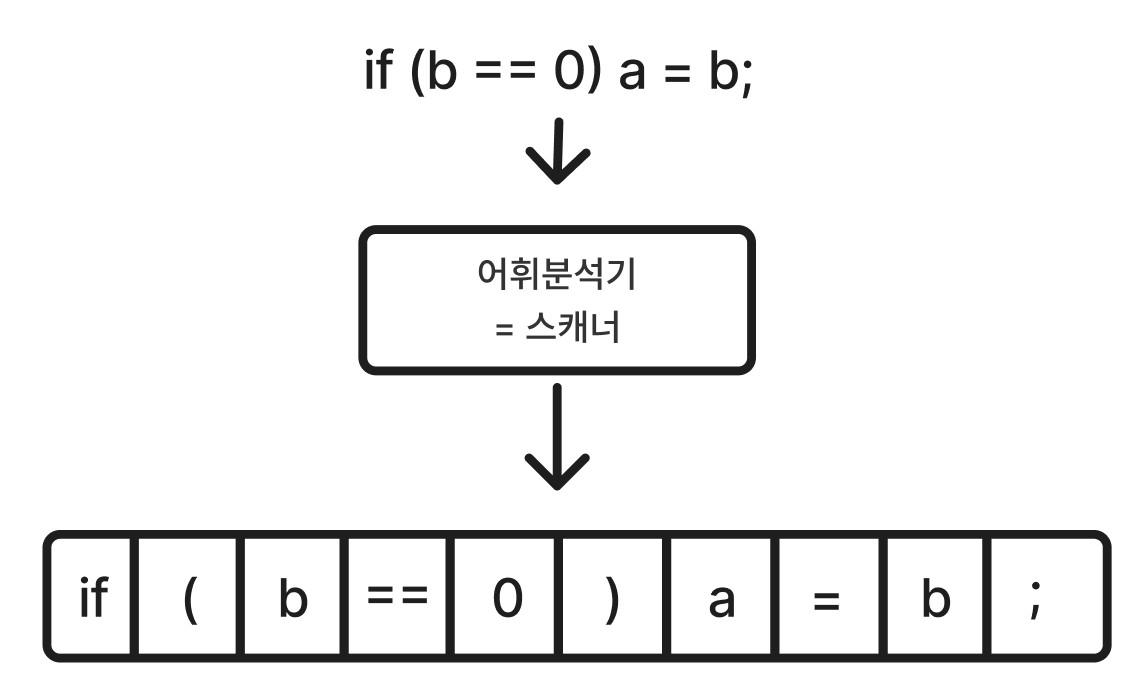
원시 프로그램을 긴 문자열로 보고 차례대로 문자를 검사하여, 의미 있는 최소 단위들로 변환하는 것이다. space 같은 것들을 제거하여 코드의 크기도 줄인다.
이때 문법적으로 의미있는 최소 단위를 토큰(Token)이라 한다.
- 식별자: x, y123, ...
- 키워드: if, else, while, for, ...
- 상수: 2, 1000, -20, 2.0, -0.01, ...
- 연산자: +, *, {, ++, <<, ...
- 문자열: "x", ...
프로그래밍 언어 제작자가 토큰을 기술하는 방법
프로그래밍언어 제작자는 정규표현식 (regular expression)을 사용해서 토큰을 설명한다.
- a: 일반 문자
- ε: 빈 스트링
- R|S: R이거나 S일 때
- RS: R 다음에 S가 나올 때
- R+: R이 1번 이상 나올 때
- R*: R이 0번이상 나올 때
- R?: R이 1번 있거나 아예 없을 때
- [a-z]: (a|b|c|...|z|) 범위 문자 중 하나
- [^ab]: 괄호속 문자들만 제외
- [^a-z]: 범위 내 문자들만 제외
- ...
토큰을 인식하는 방법
프로그래밍언어 제작자가 정규표현식을 통해 토큰을 기술하는 법을 정의했다면, 컴파일러에서는 이제 이를 인식해야한다. 이때 사용하는 것이 유한 상태 오토마타(Finite State Automata)이다.
유한상태 오토마타 정의
- 상태를 유한한 갯수까지만 가짐
- 상태간 전이를 정의
- 시작 상태 한 개와 끝 상태 여러 개를 가짐
정규 표현식과 동일한 표현력을 가졌기 때문에 어휘 분석의 기초가 되는 이론적 기반이며, 상태 전이도로 나타낸다.
ex) I = [a-zA-Z], I(I|d)* 식별자의 인식
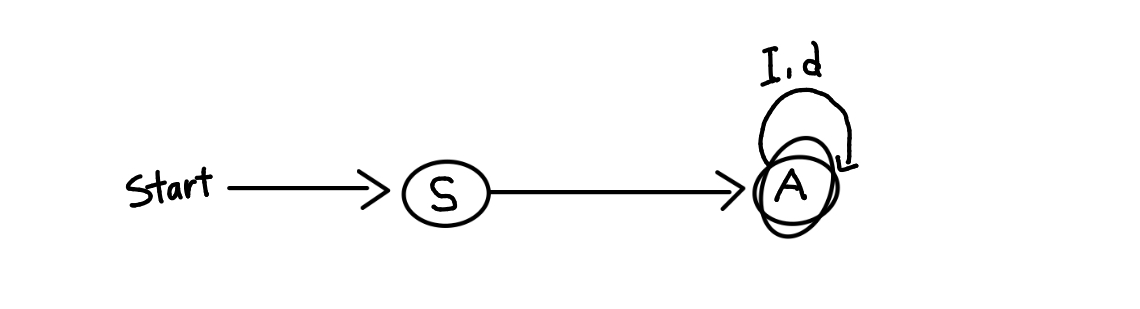
I(I|d)*
ex) d = [0-9], (+|-|ε)d+ 정수의 인식

(+|-|ε)d+
토큰 인식을 위한 처리 절차는 다음과 같다.
- 사용자가 정의한 정규 표현식을 FSA로 변환
- FSA대로 인식
ex) 토큰 "!" 또는 "!="일 때
정규표현식은 ! | (!=) 이며, FSA는 아래의 그림과 같다.

이를 통해 인식하는 코드를 작성하면 아래와 같다.(다음 문자를 확인하고, 아니면 되돌리는 ungetc 사용)
while(true){
while (isspace(ch = getchar()));
switch(ch){
case ‘!’ :
ch = getchar();
if (ch == ‘=’)
token.number = tnotequ;
else {
token.number = tnot;
ungetc(ch, stdin);
}
}
이때 DFA(Deterministic Finite Automata)는 FSA의 한 종류인데, FSA와 다르게 각 상태마다 나가는 edge가 레이블 문자에 의해 유일하게 결정된다. 엡실론이 붙은 엣지도 없다.
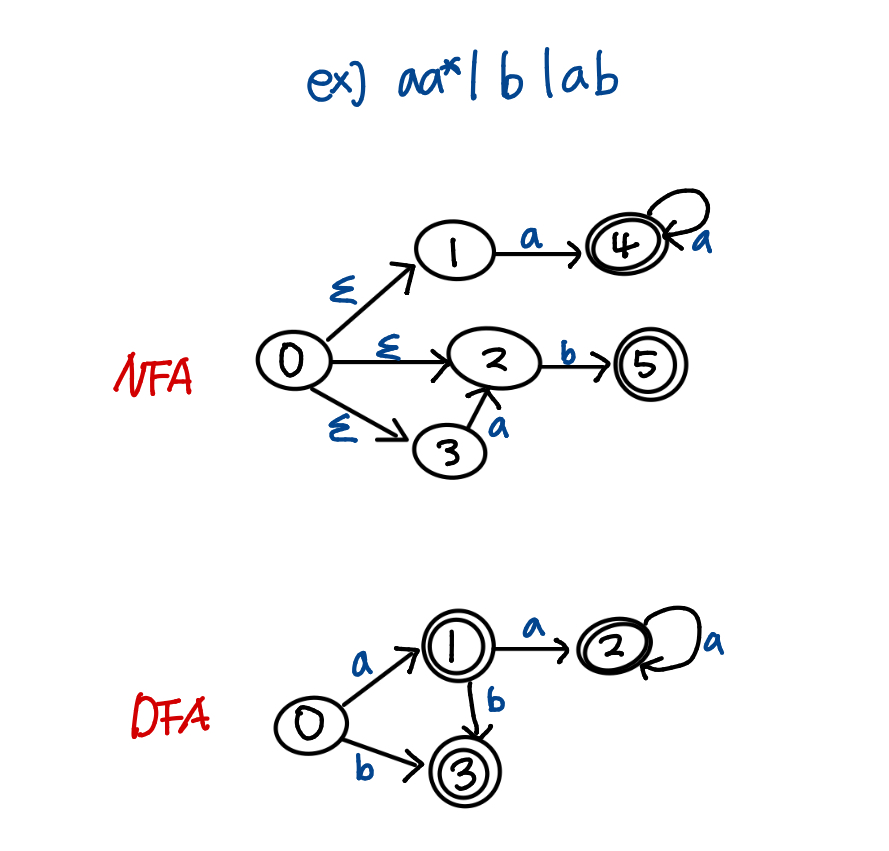
따라서 일반적인 토큰 인식 절차는 다음과 같다
- 정규 표현식 → NFA(Non-deterministic)로 변환 (NFA가 변환하기 쉬움
- NFA → DFA로 변환 (DFA가 비결정성이 없어 빠르고 구현하기 쉬움)
- DFA를 따라 인식
여러 토큰이 인식되었을 때 결정하는 방법
2개 이상의 정규표현식이 매치 될 경우가 있을 수 있다. 예를 들어 elsex = 0;이 있을 때 이는 아래 두 가지로 해석될 수 있다.
- else x = 0;
- elsex =0;
이런 경우, 정답은 없지만 주로 긴 토큰을 우선으로 처리하고, 그 후 우선선위를 비교한다.
어휘 분석 결과 내에서 토큰을 표현하는 방법
전통적인 방법으로는 Lexeme과 같이 두 부분으로 구성된 쌍으로 표현된다.
Lexeme = <토큰번호, 토큰값>
- 토큰번호: 각 토큰들의 종류를 나타내는 고유한 정수값이다.
- 토큰 값: 토큰이 프로그래머가 사용한 값을 가질 때 그 값을 말한다.
- 명칭의 토큰값은 그 자신의 스트링값이며, 상수의 토큰값은 그 자신의 상수값이다.
프로그래머가 정의한 식별자(예: x, y123)는 어휘 분석 단계에서 단일한 토큰 번호(예: 1)로 고정된다. 식별자는 사용자가 임의로 지정한 이름이므로, 이 단계에서는 단순한 문자열일 뿐 실제 의미나 용도를 파악할 수 없기 때문이다. 따라서 우선 식별자라는 타입으로 분류만 하고, 세부적인 처리는 구문 분석이나 의미 분석 단계로 미루게된다.
Lex
Lex 1975년에 레스크에 의해 발표된 어휘분석기 생성기 이다.
- 어휘분석기가 아니라 어휘분석기를 생성한다
사용자가 정의한 정규표현과 실행코드를 입력받아 c언어로 쓰여진 프로그램을 출력한다.
어휘분석기의 생성 및 동작
- lex 파일(예: test.l)을 lex에 넣는다.
- lex로부터 lex.yy.c를 받는다.
- 컴파일을 통해 lex library와 링크되고, 어휘분석기 실행파일이 완성된다.
lex의 선택 규칙은 다음과 같다
- 가장 길게 인식된 토큰을 우선으로 한다
- 인식될 수 있는 토큰의 길이가 같은 경우 먼저 나타난 규칙의 정규 표현으로 인식한다.
렉스의 구조(xx.l 또는 xx.lex)
%{ /*정의부분*/
unsigned long charCount=0, wordCount=0, lineCount =0;
%}
/*이름 정의부분*/
%% /*규칙 부분*/
[^ \t\n]+ {wordCount++; charCount+=yyleng;}
\n {charCount++; lineCount++; }
. {charCount++;}
%%
/*사용자 부 프로그램 부분*/
void main(){
FILE *file;
char fn[20];
printf("Type a input file Name: ");
scanf("%s", fn)
file=fopen(fn, "r");
if (!file) {
fprintf(stderr, "file '%s' could not be opened. \n", fn);
exit(1);
}
yyin = file;
yylex();
printf("%d %d %d %s \n", lineCount, wordCount, charCount,fn);
}
yywrap() { return 1;}- 정의부분(%{ %}): 실행코드를 C언어로 기술할 때 필요한 자료구조, 변수 상수가 들어간다.
- 이름 정의부분: 특정한 정규표현을 하나의 이름으로 정의하여 그 형태의 정규표현이 필요할 때만 쓸 수 있도록 해주는 부분
- 규칙 부분(%% %%): 토큰의 형태를 표현하는 정규표현과 그 토큰이 인식되었을 때 처리할 행위를 기술하기 위한 부분인 실행코드
- 사용자 부 프로그램 부분: 렉스 입력시 사용되는 부 프로그램들을 정의
렉스의 정규표현(일반 정규표현식 +a)
- *: 0번 이상 반복을 의미
- +: 한번이상 반복할 수 있음을 의미
- ?: 선택을 의미
- |: 택일을 위한 연산자
- []: 문자들의 클래스를 정의하는데 사용
- -: 범위 나타내는 연산자
- ^: 여집합을 표현
- “: “사이에 있는 모든 문자는 텍스트 문자로 취급
- \: [] 밖에서는 한개의 문자를 에스케이프 하기 위해, 안에서는 C언어의 에스케이프 문자열로 간주(\t, \n)
- ^: 라인의 시작을 인식
- $: 라인의 끝에서만 인식
- / : 접미문맥을 명시할 때 사용
- .: newline문자를 제외한 모든 문자들
- {} : 정의된 이름을 치환식으로 확장할 때 사용
렉스 실행코드 내의 총괄 변수와 함수
- yyleng: 매칭된 토큰의 문자열의 길이를 저장하고 있는 변수
- yytext: 매칭된 토큰의 문자열을 담은 변수
- yylval: 매칭된 토큰값을 담은 변수
- 기본값은 비어있으며, 어휘분석기가 채워서 구문분석기에 전달한다.
- yywrap(): 렉스가 입력의 끝을 만났을 때 호출하는 함수, 정상적인 경우 복귀값은 1이다.
스캐너(어휘분석기)와 파서의 관계
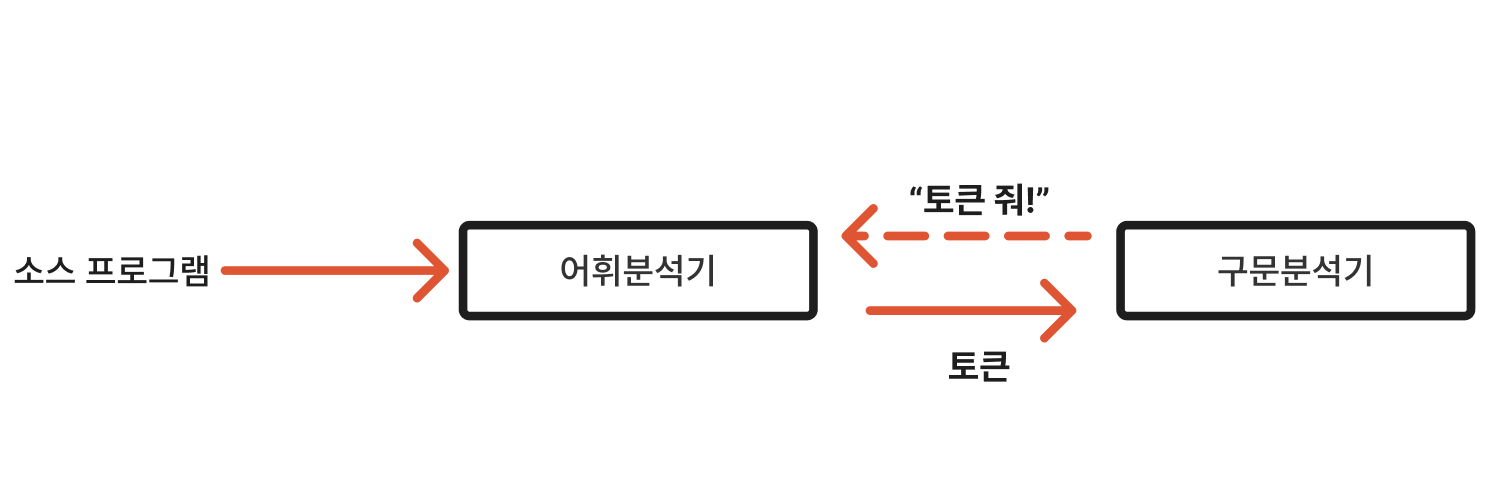
위 구조에서는 구문분석기에서 어휘 분석기의 함수 scanner()를 호출 할 때마다 다음 토큰(lexeme)이 리턴되는 구조를 취한다.
'CS > 컴파일러개론' 카테고리의 다른 글
| [컴파일러개론] syntax_derication (구문과 유도) (0) | 2025.11.09 |
|---|---|
| [컴파일러개론] 개요 (1) | 2025.10.25 |