1. 개요
이번 프로젝트에서 POST 요청을 통해 사용자의 문장을 입력받고, 해당 문장에서 명사(일반, 고유)만 추출해서 반환하는 기능이 필요하게 되었다. 이에 따라 명사 추출은 형태소 분석기 '바른'을 사용해서 구현했으며, 이를 반환하는 응답은 express로 구현했다.

이렇게 완성된 걸작(마스터피스)은 포스트맨으로도 잘 찍히고, 바른이 설치된 우분투 서버 내 로컬(html) to 로컬(express)에서도 잘 실행됐다.
그! 런! 데!

바른이 설치된 서버가 아닌 다른 곳에서 요청만 하면 자꾸 시간 경과가 뜨면서 실행이 안 됐다. 갸아악 그냥 죽음뿐
바른이 실행되는 과정에서 발생되는 딜레이가 원인이었는데, 우분투 서버에 바른을 설치할 때 지피티와 2인 3각 달리기를 했기에 분명 그 과정에서 어떤 설정 문제가 있었을 것이라는 추측뿐이었다.. 그러나 배포도 처음이고 바른 사용도 처음인 상황에서 이를 디버깅하는 것은 사실상 불가능하다는 결론을 얻었고, 결국 갈아엎은 뒤 처음부터 다시 하려고 했다.
그런데! 바른이 REST 방식의 API도 지원한다는 걸 알게 되었다 ㅎㅎ ㅋㅋ.. ㅋㅋ; ;;;;
기존에는 형태소 분석 코드를 직접 작성해서 바른의 서버로 보내고, 응답값을 받아와서 express를 통해 반환했었는데,,, 전부 필요 없어진 것;; 아무튼 에러를 해결하기 위해 바른의 REST 방식을 도입하기로 했다.
+) 바른의 동작방식이 궁금하다면 https://docs.bareun.ai/howtouse/overview/ 공식문서 참고 기기
2. 설치

도커 버전에서만 REST 방식을 지원하는 만큼 새로 서버를 생성하고, 도커를 설치한 뒤 도커 버전으로 설치를 진행했다.(기존에는 리눅스 버전으로 설치)
설치 과정은 공식 문서(24.12.11 기준)를 참고했다.
https://docs.bareun.ai/install/docker/
2.1. 도커로 바른 설치
docker pull bareunai/bareun:latest
2.2. 폴더 생성
mkdir -p ~/bareun/var
2.3. 도커 컨테이너 실행
docker run \
-d \
--restart unless-stopped \
--name bareun \
-p 5757:5757 \
-p 9902:9902 \
-v ~/bareun/var:/bareun/var \
bareunai/bareun:latest
2.4. 바른 API 키 등록
docker exec bareun /bareun/bin/bareun -reg <개인-API키>
바른 사이트의 ‘내정보’에서 API 키를 복사해서 붙여 넣으면 된다.
2.5. http://도메인:5757 확인

본인 서버의 도메인 뒤에 포트 번호(5757)를 입력해서 접속해 봤을 때, 해당 페이지가 나오면 설치가 잘 완료된 것이다.
3. 사용하자!
3.1. Request URL
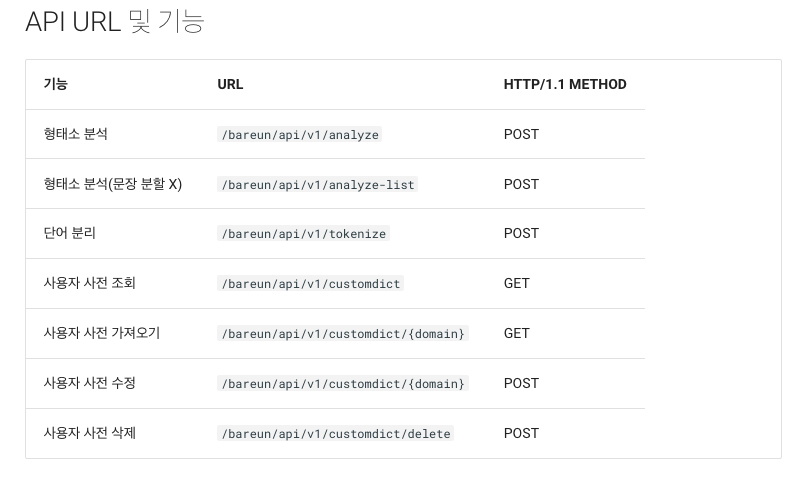
공식문서를 보면 다양한 기능을 제공해 주는 것을 확인할 수 있다. 바른이 설치된 본인 서버의 도메인에 붙여서 사용하면 된다. 나는 명사 추출 기능이 필요하기에 형태소 분석 기능(/bareun/api/v1/analyze)을 사용할 것이다.
3.2. Request Header

요청 헤더의 key 값으로는 ‘api-key’를, value 값으로는 발급받은 API 키를 넣어줘야 한다. 이를 넣지 않고 요청을 보내면 403이 반환된다. 난 토큰처럼 넣어야 하는 줄 알고 "Authorization: Bearer <API 키>“ 로 넣었다가 삽질했다 ㅎㅎ;
3.3. Request Body

요청 바디에 들어갈 데이터 형식은 위와 같다. 필요에 따라 지정하면 된다.
{
"document": {
"content": "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라만세 무궁화 삼천리 화려강산 대한사람 대한으로 길이 보전하세 ",
"language": "ko-KR"
},
"encoding_type": "UTF8",
"auto_split_sentence": false,
"auto_spacing": true,
"auto_jointing": true,
}나는 위와 같이 지정했다. 공식문서에 따르면 현재는 한국어만 지원하기 때문에 language는 생략해도 된다고 한다. 하지만 예시 문장으로 애국가를 넣는 김에 같이 넣어봤다.
3.4. Response Data

입력한 문장에 대한 형태소 분석 결과가 잘 반환되는 것을 확인할 수 있다! 전체 결과 값은 아래와 같다
{
"sentences": [
{
"text": {
"content": "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라만세 무궁화 삼천리 화려강산 대한사람 대한으로 길이 보전하세",
"beginOffset": 0,
"length": 169
},
"tokens": [
{
"text": {
"content": "동해물과",
"beginOffset": 0,
"length": 12
},
"morphemes": [
{
"text": {
"content": "동해",
"beginOffset": 0,
"length": 6
},
"tag": "NNP",
"probability": 0.653207362,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "물",
"beginOffset": 6,
"length": 3
},
"tag": "NNG",
"probability": 0.977748811,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "과",
"beginOffset": 9,
"length": 3
},
"tag": "JC",
"probability": 0.967664361,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "동해",
"tagged": "동해/NNP+물/NNG+과/JC",
"modified": ""
},
{
"text": {
"content": "백두산이",
"beginOffset": 13,
"length": 12
},
"morphemes": [
{
"text": {
"content": "백두산",
"beginOffset": 13,
"length": 9
},
"tag": "NNP",
"probability": 0.955397725,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "이",
"beginOffset": 22,
"length": 3
},
"tag": "JKS",
"probability": 0.983972728,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "백두산",
"tagged": "백두산/NNP+이/JKS",
"modified": ""
},
{
"text": {
"content": "마르고",
"beginOffset": 26,
"length": 9
},
"morphemes": [
{
"text": {
"content": "마르",
"beginOffset": 26,
"length": 6
},
"tag": "VV",
"probability": 0.992255449,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "고",
"beginOffset": 32,
"length": 3
},
"tag": "EC",
"probability": 0.99395144,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "마르",
"tagged": "마르/VV+고/EC",
"modified": ""
},
{
"text": {
"content": "닳도록",
"beginOffset": 36,
"length": 9
},
"morphemes": [
{
"text": {
"content": "닳",
"beginOffset": 36,
"length": 3
},
"tag": "VV",
"probability": 0.982538939,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "도록",
"beginOffset": 39,
"length": 6
},
"tag": "EC",
"probability": 0.991895437,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "닳",
"tagged": "닳/VV+도록/EC",
"modified": ""
},
{
"text": {
"content": "하느님이",
"beginOffset": 46,
"length": 12
},
"morphemes": [
{
"text": {
"content": "하느님",
"beginOffset": 46,
"length": 9
},
"tag": "NNG",
"probability": 0.982093,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "이",
"beginOffset": 55,
"length": 3
},
"tag": "JKS",
"probability": 0.991373062,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "하느님",
"tagged": "하느님/NNG+이/JKS",
"modified": ""
},
{
"text": {
"content": "보우하사",
"beginOffset": 59,
"length": 12
},
"morphemes": [
{
"text": {
"content": "보우하",
"beginOffset": 59,
"length": 9
},
"tag": "VV",
"probability": 0,
"outOfVocab": "IN_BUILTIN_DICT"
},
{
"text": {
"content": "사",
"beginOffset": 68,
"length": 3
},
"tag": "EC",
"probability": 0.960934043,
"outOfVocab": "OUT_OF_VOCAB"
}
],
"lemma": "보우하",
"tagged": "보우하/VV+사/EC",
"modified": ""
},
{
"text": {
"content": "우리나라만세",
"beginOffset": 72,
"length": 18
},
"morphemes": [
{
"text": {
"content": "우리나라",
"beginOffset": 72,
"length": 12
},
"tag": "NNG",
"probability": 0.9666152,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "만세",
"beginOffset": 84,
"length": 6
},
"tag": "NNG",
"probability": 0.971511126,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "우리나라",
"tagged": "우리나라/NNG+만세/NNG",
"modified": ""
},
{
"text": {
"content": "무궁화",
"beginOffset": 91,
"length": 9
},
"morphemes": [
{
"text": {
"content": "무궁화",
"beginOffset": 91,
"length": 9
},
"tag": "NNG",
"probability": 0.980439723,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "무궁화",
"tagged": "무궁화/NNG",
"modified": ""
},
{
"text": {
"content": "삼천리",
"beginOffset": 101,
"length": 9
},
"morphemes": [
{
"text": {
"content": "삼천리",
"beginOffset": 101,
"length": 9
},
"tag": "NNG",
"probability": 0.950299263,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "삼천리",
"tagged": "삼천리/NNG",
"modified": ""
},
{
"text": {
"content": "화려강산",
"beginOffset": 111,
"length": 12
},
"morphemes": [
{
"text": {
"content": "화려강산",
"beginOffset": 111,
"length": 12
},
"tag": "NNG",
"probability": 0.568273842,
"outOfVocab": "OUT_OF_VOCAB"
}
],
"lemma": "화려강산",
"tagged": "화려강산/NNG",
"modified": ""
},
{
"text": {
"content": "대한사람",
"beginOffset": 124,
"length": 12
},
"morphemes": [
{
"text": {
"content": "대한",
"beginOffset": 124,
"length": 6
},
"tag": "NNP",
"probability": 0.722762644,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "사람",
"beginOffset": 130,
"length": 6
},
"tag": "NNG",
"probability": 0.983198285,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "대한",
"tagged": "대한/NNP+사람/NNG",
"modified": ""
},
{
"text": {
"content": "대한으로",
"beginOffset": 137,
"length": 12
},
"morphemes": [
{
"text": {
"content": "대한",
"beginOffset": 137,
"length": 6
},
"tag": "NNP",
"probability": 0.910932183,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "으로",
"beginOffset": 143,
"length": 6
},
"tag": "JKB",
"probability": 0.997060418,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "대한",
"tagged": "대한/NNP+으로/JKB",
"modified": ""
},
{
"text": {
"content": "길이",
"beginOffset": 150,
"length": 6
},
"morphemes": [
{
"text": {
"content": "길",
"beginOffset": 150,
"length": 3
},
"tag": "NNG",
"probability": 0.980661035,
"outOfVocab": "IN_WORD_EMBEDDING"
},
{
"text": {
"content": "이",
"beginOffset": 153,
"length": 3
},
"tag": "JKS",
"probability": 0.933542132,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "길",
"tagged": "길/NNG+이/JKS",
"modified": ""
},
{
"text": {
"content": "보전하세",
"beginOffset": 157,
"length": 12
},
"morphemes": [
{
"text": {
"content": "보전하",
"beginOffset": 157,
"length": 9
},
"tag": "VV",
"probability": 0,
"outOfVocab": "IN_BUILTIN_DICT"
},
{
"text": {
"content": "세",
"beginOffset": 166,
"length": 3
},
"tag": "EF",
"probability": 0.785468221,
"outOfVocab": "IN_WORD_EMBEDDING"
}
],
"lemma": "보전하",
"tagged": "보전하/VV+세/EF",
"modified": ""
}
],
"refined": "동해물과 백두산이 마르고 닳도록 하느님이 보우하사 우리나라만세 무궁화 삼천리 화려강산 대한사람 대한으로 길이 보전하세"
}
],
"language": "ko_KR"
}
request body에 넣은 애국가 문장에 대한 형태소 분석 결과를 JSON으로 반환해 준 것이다.
이렇게 바른의 REST 방식을 도입함으로써 형태소 분석 결과를 간단하게 얻을 수 있게 되었다.
그러나! 아직 끝이 아니다. 위의 결과는 문장에 대한 전체 형태소 분석 결과를 반환했을 뿐, 나는 명사를 추출해서 사용해야 하기 때문이다.
4. 명사 추출 구현
async function fetchGetNouns() {
const userInput = document.getElementById('userInputText').value;
try {
const response = await fetch('http://도메인:5757/bareun/api/v1/analyze', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'api-key': 'koba-바른API키',
},
body: JSON.stringify({
document: {
content: userInput,
language: 'ko-KR',
},
encoding_type: 'UTF8',
auto_split_sentence: false,
auto_spacing: true,
auto_jointing: true,
}),
});
if (!response.ok) {
throw new Error('서버 요청 실패');
}
const data = await response.json();
const nouns = [];
data.sentences.forEach(sentence => {
sentence.tokens.forEach(token => {
token.morphemes.forEach(morpheme => {
if (morpheme.tag === 'NNG' || morpheme.tag === 'NNP') {
nouns.push(morpheme.text.content);
}
});
});
});
console.log(`입력한 문장: ${userInput}`);
console.log(`추출된 명사: ${nouns}`);
} catch (error) {
console.error('Error:', error);
}
}나는 일반명사와 고유명사만을 필요로 하고 있기 때문에 품사태그가 NNG(일반명사), NNP(고유명사)인 값들만 추출해서 사용하면 된다.
이에 따라 삼중 forEach로 원하는 값을 추출하기로 했다. "저렇게 더러운 삼중 forEach를 쓰는 게 맞나요?" 라고 묻는다면 나도 모른다. 난 그저 일반명사와 고유명사를 얻고 싶었을 뿐이다.

아무튼 기사 제목을 넣어보면 일반명사와 고유명사가 추출되는 것을 확인할 수 있다. 야호 만족 만족
5. 결론
이전에는 우분투 서버에 node, npm, 바른, 바른 라이브러리(npm) 전부 설치한 뒤, 형태소 분석 코드를 직접 작성해서 서버로 보내 응답받고, express로 백엔드 구축해서 배포하고 기타 세팅도 하는 등등등 귀찮은 과정을 거쳐야 최종 반환 값을 얻을 수 있었다면, 이제는 엔드포인트만 찍으면 바로 반환 값을 얻을 수 있다. 휴휴휴휴,,, 너무 편해~~ 심지어 에러도 없어~~~
공식문서를 잘 읽었으면 첨부터 편하게 썼을 텐데 ㅎ.ㅎ 아무튼 좋은 경험이었다,,
'개발 지식' 카테고리의 다른 글
| Mac M1에서 정적 분석기 infer 사용하기 (0) | 2025.05.27 |
|---|---|
| [리액트] i18next 통해 다국어를 지원해 보자 (4) | 2024.08.29 |
| Chakra(차크라) UI를 사용해 보자(with React) (0) | 2024.07.18 |
| [TS] interface와 type alias의 차이점은 무엇인가? (0) | 2024.07.06 |